Modélisation logique des données
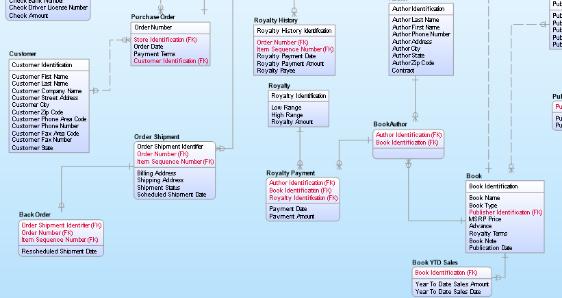
Qu’est-ce qu’un modèle logique de données ?
En tant que représentation graphique des besoins en informations pour un domaine d’activité donné, un modèle logique de données est construit en prenant les descriptions de données fournies dans un modèle conceptuel de données et en introduisant des éléments associés, des définitions et un contexte plus large pour la structure des données.
Cette étape est importante, car si le modèle conceptuel de données plus rationnel est plus facile à communiquer, l’absence de contexte peut rendre difficile le passage de la modélisation à la mise en œuvre. Des détails supplémentaires sont nécessaires pour soutenir cette progression. Il s’agit notamment de la définition des attributs possédés, des clés primaires, des clés étrangères, de la cardinalité des relations et de la description des entités et des classes. À ce stade, la nature des relations entre les données est établie et définie, et les données provenant de différents systèmes sont normalisées.
Quel est l’objectif d’un modèle logique de données ?
À ce stade, la fonction principale du modèle de données est de visualiser les éléments de données et la façon dont ils sont liés les uns aux autres. La modélisation logique des données permet également de détailler les attributs associés à un élément de données. Par exemple, un modèle logique de données spécifierait la nature d’un élément de données, c’est-à-dire le nom du compte (chaîne de caractères), le numéro de compte (nombre entier).
Quand faut-il envisager un modèle logique de données ?
Les trois types de modèles de données fournissent des degrés croissants de contexte et de détail, de sorte que nous pouvons afficher leur utilisation de manière séquentielle. Par conséquent, un modèle logique de données doit être envisagé une fois que le modèle conceptuel de données a été construit.
Cette étape plus structurée de la modélisation des données est plus pertinente pendant la conception de l’application, lorsqu’elle peut servir de mécanisme de communication dans les environnements plus techniques où travaillent les analystes et les concepteurs de bases de données. Elle nous aide à comprendre les détails des données dans une plus large mesure que les modèles conceptuels de données, sans toutefois fournir de perspective sur la façon dont elle devrait être mise en œuvre.
Comme pour la modélisation conceptuelle des données, cela signifie que les équipes ne sont pas liées par des considérations technologiques. Ce point est important, car la technologie dans les organisations est souvent de nature dynamique.
Pourquoi utiliser un modèle logique de données ?
Pour comprendre quand et pourquoi un modèle logique de données est pertinent, il suffit de considérer le public visé par le modèle, à savoir les analystes de bases de données, les analystes système et les concepteurs. Le public visé par la modélisation logique des données et sa place dans le processus de conception des applications font que l’exclusion du contexte et des détails au profit de l’accessibilité est moins pertinente. La couche supplémentaire de détails (par rapport à la modélisation conceptuelle des données) est le contexte dont les architectes ont besoin pour s’assurer que les nouvelles applications sont compatibles avec les données qu’elles englobent. Essentiellement, un modèle logique de données fournit les bases nécessaires à la conception de la base de données de production.
Sans un modèle logique de données, les concepteurs ne peuvent réellement déterminer les exigences d’une nouvelle application qu’à mesure qu’ils avancent. Cela signifie souvent qu’il faudra travailler avec des éléments de données non organisés, ce qui rendra plus probable l’oubli de ces exigences. Ainsi, ignorer cette étape de modélisation logique des données au profit de la construction d’un modèle physique de données peut conduire à une mauvaise conception de la base de données et à des applications qui ne fonctionnent pas comme prévu. Pour remédier à ces erreurs, il est nécessaire d’adopter une approche réactive qui peut ralentir la commercialisation et augmenter les coûts totaux associés au processus de développement.
De plus, la nature agnostique de la technologie d’un modèle logique de données aide les organisations à établir les possibilités d’amélioration des processus. Cela signifie que les nouvelles applications peuvent être conçues pour être aussi efficaces que possible, plutôt que d’être aussi efficaces que les contraintes technologiques actuelles le permettent.
Avantages de la modélisation logique des données
Aider les organisations à identifier les domaines d’amélioration des processus métiers
Concevoir des applications bien informées
Réduire les coûts et accroître l’efficacité
Fournir une base pour les modèles futurs
Créer de meilleurs modèles avec erwin
Les données sont au cœur de l’activité d’erwin depuis plus de 30 ans. Nous sommes considérés comme le leader du marché de la modélisation des données. Cette expertise a permis de créer une plateforme de modélisation des données parfaite pour répondre aux besoins de modélisation à chaque étape, conceptuelle, logique et physique, du processus de modélisation des données.
erwin Data Modeler de Quest permet aux parties prenantes commerciales et techniques de collaborer à la conception et à la mise en œuvre de nouveaux systèmes. Elles bénéficient aussi de fonctionnalités telles que la prise en charge des solutions NoSQL et la collecte automatique de métadonnées, qui réduisent considérablement les délais de mise en œuvre.